Anthropic大手笔租下SpaceX顶级数据中心!深扒协议细节:22万块GPU是个什么水平?
全球AI算力竞赛再掀巨浪,头部玩家的“军备”升级从未如此迅猛。
美东时间周三,AI独角兽Anthropic官宣重磅合作,正式租下SpaceX旗下Colossus 1数据中心全部算力,拿下了这座曾支撑xAI训练Grok超算的“顶级算力堡垒”。
根据协议,这笔合作将在1个月内为Anthropic带来超300兆瓦新增算力,等效22万块英伟达GPU,直接刷新行业算力扩容纪录。
此番联手,不仅让长期因算力不足受限、频繁限流的Anthropic一举摆脱资源桎梏,更让马斯克旗下SpaceX深度入局AI算力租赁赛道。
那么,22万GPU、300兆瓦容量究竟意味着什么?这笔“天价”算力交易背后藏着怎样的博弈?本文将为您深度拆解这场AI算力圈的关键变局。
签约主体:SpaceXAI与Anthropic
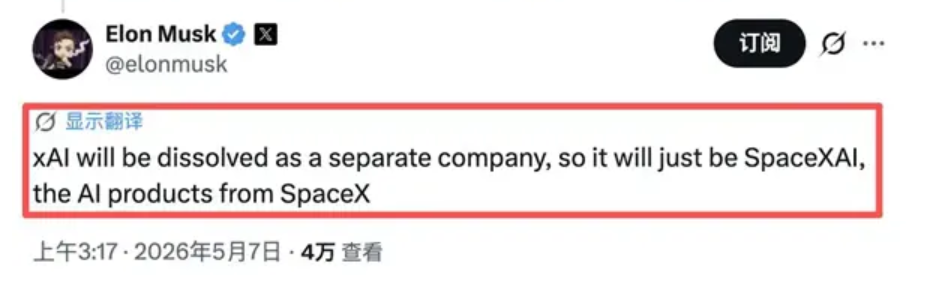
值得注意的是,就在这场协议公布后,马斯克在X上发表的另一篇文章中表示,xAI“将作为一家独立公司解散”,并将更名为 SpaceXAI。
算力规模:Anthropic在一份声明中表示,该协议使其“在一个月内获得超过300兆瓦的新产能”。
根据xAI官方数据,这次Anthropic租赁的Colossus 1是全球最大的AI数据中心之一,配备了超过22万块英伟达GPU,其中包括密集部署的H100、H200和下一代GB200加速器。

数据中心位置:美国田纳西州孟菲斯
交付时间:一个月内
重要性:
对于Anthropic:
在此之前,Anthropic公开算力估算仅不足10万H100当量,明显落后OpenAI和谷歌DeepMind等同行。这次新增22万张GPU算力后,总算力直接追平甚至超越部分大厂,为下一代大模型训练、多模态升级、企业级大规模部署提供硬件底气。
对于SpaceX:
a.闲置顶级算力直接变现:Colossus 1 原本为xAI训练而建,xAI并入SpaceX后训练主力迁移至 Colossus 2,1号机群处于高投入、高耗电、低产出的闲置状态。租给 Anthropic后,这一闲置产能可直接实现算力变现,降低AI业务亏损率,为IPO提供强现金流故事。
b.“太空算力”梦想更进一步:双方联合研发轨道级算力的约定,意味着SpaceX把“数据中心上天”从概念朝着工程路线更进了一步。
用户直接收益;
1.Anthropic将Claude Code针对 Pro、Max、Team 和企业计划的服务时长限制从原来的 5 小时提升至 10 小时。
2.Anthropic将取消 Claude Code Pro 和 Max 账户的“高峰时段使用限制”规定。
3.Anthropic将大幅提高Claude Opus 模型的API 请求上限,具体数据如下面表格所示:

300兆瓦相当于什么概念
如SpaceX所说,300兆瓦的功耗相当于22万张英伟达GPU。
我们以当前主流AI训练芯片(如H100)为假设基准来进行推算:单H100 GPU典型功耗大约为700W,那么22万片GPU本体功耗大约为154MW,剩下电力用于冷却、供电损耗、网络与管理系统。
当然,实际上SpaceX还使用了H200、GB100等芯片,不同芯片的功耗不同,所以实际的用电数据可能略有出入。
直观来看,300兆瓦相当于一个中型城市或大型工业园区的用电负荷。一般来说,300MW可满足约20–30万户家庭的日常用电。换句话说,即一个中型城市的全部居民用电都用于给Colossus 1这一个数据中心发电。
而和同行对比的话,根据摩根士丹利、高盛、Bernstein等行业分析师推算,各大AI大厂的全网全域可调度总算力当量数据约为:
OpenAI:预估在15万–20万张H100当量(分散在多个集群,非一次性可用)
Google DeepMind:约10万–15万张H100当量
Meta(LLaMA):约8万–10万张H100当量
Anthropic(与SpaceXAI签约之前):不足10万张H100当量(所以此前一直限流)

(文章来源:财联社)
声明:
- 风险提示:以上内容仅来自互联网,文中内容或观点仅作为原作者或者原网站的观点,不代表本站的任何立场,不构成与本站相关的任何投资建议。在作出任何投资决定前,投资者应根据自身情况考虑投资产品相关的风险因素,并于需要时咨询专业投资顾问意见。本站竭力但不能证实上述内容的真实性、准确性和原创性,对此本站不做任何保证和承诺。
- 本站认真尊重知识产权及您的合法权益,如发现本站内容或相关标识侵犯了您的权益,请您与我们联系删除。









推荐文章: